
As a C-level executive, it’s becoming clear to me that NoSQL databases and Machine Learning toolsets like Spark are going to play an increasingly big role in data-driven business models, low-latency architecture & rapid application development (projects that can be done in 8-12 weeks not years).
The best practice firms are making this technology shift as decreasing storage costs have led to an explosion of big data. Commodity cluster software, like Hadoop, has made it 10-20x cheaper to store large datasets.
After spending two days at the leading NoSQL provider MongoDB World event in NYC, I was pleasantly surprised to see the amount of innovation and size of user community around document centric databases like MongoDB.
It doesn’t take genius to realize that data driven business models, high volume data feeds, mobile first customer engagement, and cloud are creating new distributed database requirements. Today’s modern online and mobile applications need continuous availability, cost effective scalability and high-speed analytics to deliver an engaging customer experience.
Legacy relational databases fail to meet the requirements of digital and online applications for the following reasons:
Data-driven
- 90% data created in last 2 years (e.g., machine generated)
- 80% enterprise data is unstructured (e.g., social media)
- Unstructured data growing 2X rate of structured data
Time/Speed
- Development methods shifted from waterfall (12-24 months) to agile
- Companies like Facebook + Amazon are shipping code multiple times a day (I heard that Facebook does 100+ patch releases a day; Amazon does a production push every 15 seconds on the average…which sounds pretty insane).
Scale/Global
- Engagement at Scale… User bases shifted from internal (thousands) to external (millions)
- 24/7 continuous availability… Can’t go down
- Linear scalability across data centers
Cloud Economics
- Shift to open-source business models to pay for value over time
- Ability to leverage cloud and commodity architectures to lower infrastructure costs
Relational databases laid the foundation for what we do in every corporation:
- Rich and fast access to the data, using an expressive query language and secondary indexes
- Strong consistency, so you know you’re always getting the most up to date version of the data
The market for NoSQL is predicated on the fact that relational databases are not built for the new world – unstructured data, rapid development and rapid deployment, mobile and cloud-ready. They are:
- Built for waterfall dev cycles, structured data
- Built for internal users, not for millions of users all across the global
- Mostly for systems of record, not for the emerging systems of engagement
- License fee heavy… vendors who want large license fees upfront
So while RDMS are strong in terms of data access and consistency, they lack in flexibility, scalability and performance for billions of transactions. Enter NoSQL.
What is NoSQL?
NoSQL platforms are addressing the Big Data scalability problem… Solutions must have elasticity in three dimensions:
- Data Storage;
- Compute; and
- Ability to Serve Large Number of Users (Read and Write).
NoSQL is an umbrella term for a broad class of database management systems that relax some of the tradition design constraints of traditional relational database management systems (RDBMS) in order to meet goals of more cost-effective scalability, flexible tradeoffs of availability vs. consistency (as described by the CAP theorem), and flexibility for data structures that don’t fit well into the relational model, such as key-value data, graphs and documents. NoSQL databases typically don’t offer ACID transactions nor full SQL capability.
NoSQL databases expose different information models, including key-value records, JSON or XML documents as records, or graph-oriented data. They expose corresponding programmer APIs and sometimes custom query languages that may or may not be SQL-based. However, a recent trend in this industry is the re-introduction of restricted SQL dialects to support the large user community accustomed to SQL and improving support for transactions.
As an example of a scenario where a NoSQL database is a good fit, an event log for a web site might be captured in a key-value store, where fast appends and key-based retrievals are required, but not updates nor joins.
What are the Right Use Cases for NoSQL?
The typical NoSQL use cases are shown below.
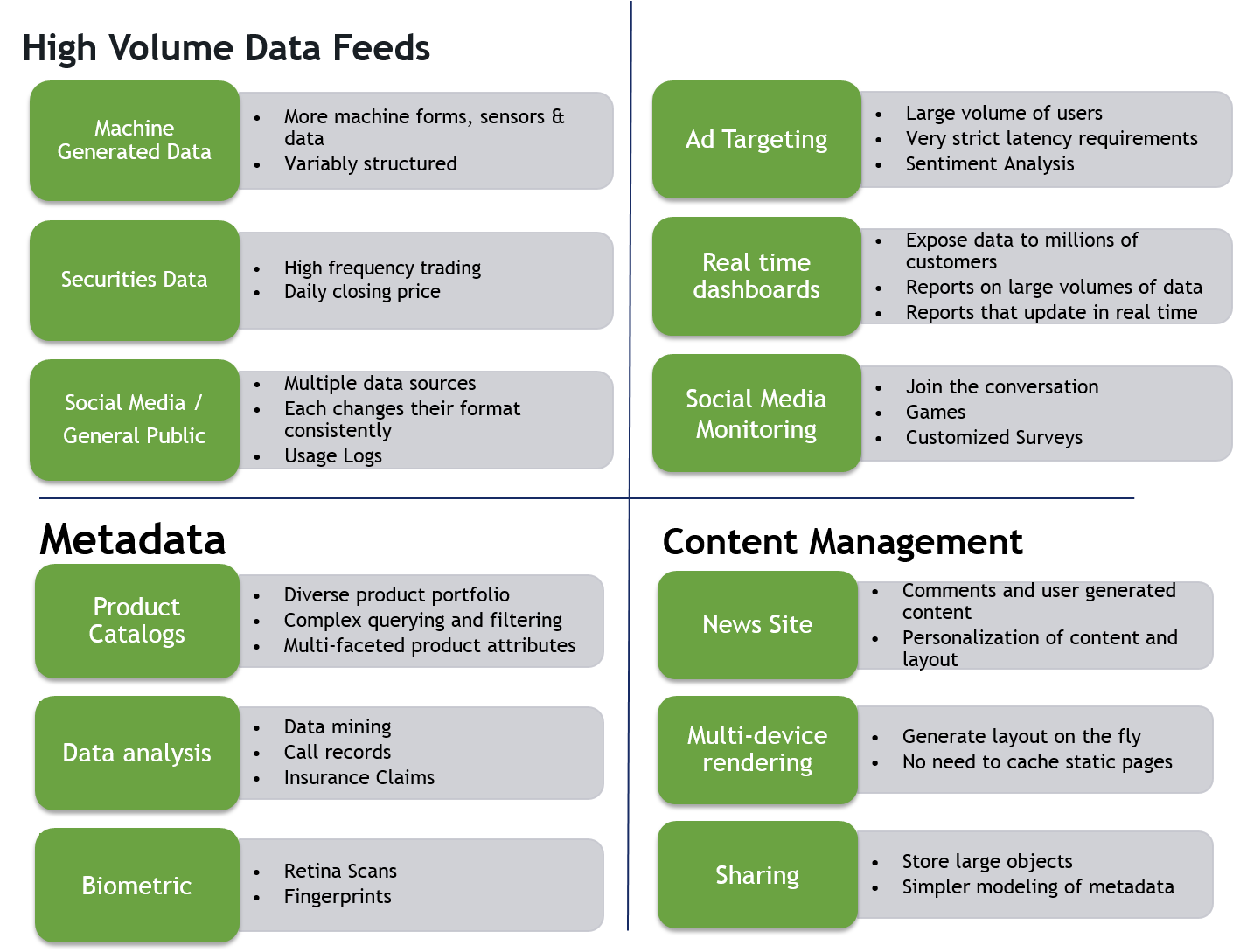
The NoSQL ecosystem
The better known NoSQL databases are MongoDB, HBase, Cassandra, Couchbase, Aerospike, DynamoDB, MarkLogic, Riak, Redis, Accumulo, and Datatomic. Of these, HBase and Accumulo are closely tied to Hadoop than the others, as both use HDFS for persistent storage and Zookeeper for service federation.
NoSQL database features typically include the following:

Source: MongoDB
MongoDB
MongoDB is a document-oriented NoSQL database where each record is a JSON document. It has a rich, Javascript-based query language that exploits the implicit structure of JSON. MongoDB supports sharding for improved scalability and resilience. It is most popular for small to large data sets and less commonly used for very large data sets.
MongoDB is useful if you have the following needs:
- Large number of objects to store – Sharding lets you split objects across multiple servers
- High write / read throughput and data distribution — Sharding + Replication lets you scale read and write traffic across multiple servers, multiple tenants, or data centers
- Low latency access — Memory mapped storage engine caches documents in RAM, enabling in-memory operations. Data locality of documents significantly improves latency over join-based approaches
- Variable data in objects — Dynamic schema and JSON data model enable flexible data storage without sparse tables or complex joins, and provide for an intuitive query language
- Cloud based deployment — Sharding and replication let you work around hardware limitations in the cloud.
HBase
HBase is a distributed, column-oriented database, where each cell is versioned (a configurable number of previous values is retained). HBase provides Bigtable-like capabilities on top of Hadoop. SQL queries (but not updates) are supported using Hive, but with high latency. Eventually, Impala will also support Hive queries with lower latency. Like many NoSQL databases, HBase does not support complex transactions, SQL, or ACID transactions. However, HBase offers high read and write performance and is used in several large applications, such as Facebook’s Messaging Platform. By default, HBase uses HDFS for durable storage, but it layers on top of this storage fast record-level queries and updates, which “raw” HDFS doesn’t support. Hence, HBase is useful when fast, record-level queries and updates are required, but storage in HDFS is desired for use with Pig, Hive, or other MapReduce-based tools.
Cassandra
Cassandra is the most popular NoSQL database for very large data sets. It is a key-value, clustered database that uses column-oriented storage, sharding by key ranges, and redundant storage for scalability in both data sizes and read/write performance, as well as resiliency against “hot” nodes and node failures. Cassandra has configurable consistency vs. availability (CAP theorem) tradeoffs, such as a tunable quorum model for writes.
Some users of Cassandra include Target and Facebook. DataStax is the firm who provides the support and tools behind this open source project.
MarkLogic
MarkLogic is a document-oriented database platform that has a schema-agnostic data model for storing and managing XML, JSON, RDF, and Geospatial data. It uses a distributed, scale-out architecture, claims to provide ACID transactions, and government-certified security.
DynamoDB
DynamoDB is Amazon’s highly scalable and available, key-value, NoSQL database. DynamoDB was one of the earliest NoSQL databases and papers written about it influenced the design of many other NoSQL databases, such as Cassandra.
Couchbase
Couchbase is a key-value NoSQL database that is well-suited for mobile applications where a copy of a data set is resident on many devices, where changes can be performed on any copy, and copies are synchronized when connectivity is available. Think of how an email client works with local copies of your email history and corresponding email servers.
Redis
Redis is a key-value store with the specific support for fundamental data structures as values, including strings, hash maps, lists, sets, and sorted sets, whereas most key-value stores have limited understanding of a value’s meaning, except to represent the value as column cells, if many cases. For this reason, Redis is sometimes called a data structure server. Redis keeps all data in memory, which improves performance, but limits the data set sizes it can manage. Durability is optional, by periodic flushing to disk or writing updates to an append log. Master slave replication is also supported.
Datomic
Datomic is a newer entrant in the NoSQL landscape with a unique data model that remembers the state of the database at all points in the past, making historical reconstruction of events and state trivial. Many standard database operations are supported, including joins and ACID transactions. Deployments are distributed, elastic, highly available.
Riak
Riak is a fault-tolerant, distributed, key-value NoSQL database designed for large-scale deployments in cloud or hosted environments. A Riak database is masterless, with no single points of failure. It is resilient against the failure of multiple nodes and nodes can be added or removed easily. Riak is also optimized for read and write-intensive applications.
Additional References and Notes
What is Hadoop? Explaining Big Data to the C-level
disruptivedigital.wordpress.com — digital use cases where NoSQL will play a critical role.
sdjfklsdjf;sdj
As As a C-level executive, it’s becoming clear to me that NoSQL databases and Machine Learning toolsets like Spark are going to play an increasingly big role in data-driven business models, low-latency architecture & rapid application development (projects that can be done in 8-12 weeks not years).
The best practice firms are making this technology shift as decreasing storage costs have led to an explosion of big data. Commodity cluster software, like Hadoop, has made it 10-20x cheaper to store large datasets.
After spending two days at the leading NoSQL provider MongoDB World event in NYC, I was pleasantly surprised to see the amount of innovation and size of user community around document centric databases like MongoDB.
It doesn’t take genius to realize that data driven business models, high volume data feeds, mobile first customer engagement, and cloud are creating new distributed database requirements. Today’s modern online and mobile applications need continuous availability, cost effective scalability and high-speed analytics to deliver an engaging customer experience.
Legacy relational databases fail to meet the requirements of digital and online applications for the following reasons:
Data-driven
- 90% data created in last 2 years (e.g., machine generated)
- 80% enterprise data is unstructured (e.g., social media)
- Unstructured data growing 2X rate of structured data
Time/Speed
- Development methods shifted from waterfall (12-24 months) to agile
- Companies like Facebook + Amazon are shipping code multiple times a day (I heard that Facebook does 100+ patch releases a day; Amazon does a production push every 15 seconds on the average…which sounds pretty insane).
Scale/Global
- Engagement at Scale… User bases shifted from internal (thousands) to external (millions)
- 24/7 continuous availability… Can’t go down
- Linear scalability across data centers
Cloud Economics
- Shift to open-source business models to pay for value over time
- Ability to leverage cloud and commodity architectures to lower infrastructure costs
Relational databases laid the foundation for what we do in every corporation:
- Rich and fast access to the data, using an expressive query language and secondary indexes
- Strong consistency, so you know you’re always getting the most up to date version of the data
The market for NoSQL is predicated on the fact that relational databases are not built for the new world – unstructured data, rapid development and rapid deployment, mobile and cloud-ready. They are:
- Built for waterfall dev cycles, structured data
- Built for internal users, not for millions of users all across the global
- Mostly for systems of record, not for the emerging systems of engagement
- License fee heavy… vendors who want large license fees upfront
So while RDMS are strong in terms of data access and consistency, they lack in flexibility, scalability and performance for billions of transactions. Enter NoSQL.
What is NoSQL?
NoSQL platforms are addressing the Big Data scalability problem… Solutions must have elasticity in three dimensions:
- Data Storage;
- Compute; and
- Ability to Serve Large Number of Users (Read and Write).
NoSQL is an umbrella term for a broad class of database management systems that relax some of the tradition design constraints of traditional relational database management systems (RDBMS) in order to meet goals of more cost-effective scalability, flexible tradeoffs of availability vs. consistency (as described by the CAP theorem), and flexibility for data structures that don’t fit well into the relational model, such as key-value data, graphs and documents. NoSQL databases typically don’t offer ACID transactions nor full SQL capability.
NoSQL databases expose different information models, including key-value records, JSON or XML documents as records, or graph-oriented data. They expose corresponding programmer APIs and sometimes custom query languages that may or may not be SQL-based. However, a recent trend in this industry is the re-introduction of restricted SQL dialects to support the large user community accustomed to SQL and improving support for transactions.
As an example of a scenario where a NoSQL database is a good fit, an event log for a web site might be captured in a key-value store, where fast appends and key-based retrievals are required, but not updates nor joins.
What are the Right Use Cases for NoSQL?
The typical NoSQL use cases are shown below.
The NoSQL ecosystem
The better known NoSQL databases are MongoDB, HBase, Cassandra, Couchbase, Aerospike, DynamoDB, MarkLogic, Riak, Redis, Accumulo, and Datatomic. Of these, HBase and Accumulo are closely tied to Hadoop than the others, as both use HDFS for persistent storage and Zookeeper for service federation.
NoSQL database features typically include the following:
Source: MongoDB
MongoDB
MongoDB is a document-oriented NoSQL database where each record is a JSON document. It has a rich, Javascript-based query language that exploits the implicit structure of JSON. MongoDB supports sharding for improved scalability and resilience. It is most popular for small to large data sets and less commonly used for very large data sets.
MongoDB is useful if you have the following needs:
- Large number of objects to store – Sharding lets you split objects across multiple servers
- High write / read throughput and data distribution — Sharding + Replication lets you scale read and write traffic across multiple servers, multiple tenants, or data centers
- Low latency access — Memory mapped storage engine caches documents in RAM, enabling in-memory operations. Data locality of documents significantly improves latency over join-based approaches
- Variable data in objects — Dynamic schema and JSON data model enable flexible data storage without sparse tables or complex joins, and provide for an intuitive query language
- Cloud based deployment — Sharding and replication let you work around hardware limitations in the cloud.
HBase
HBase is a distributed, column-oriented database, where each cell is versioned (a configurable number of previous values is retained). HBase provides Bigtable-like capabilities on top of Hadoop. SQL queries (but not updates) are supported using Hive, but with high latency. Eventually, Impala will also support Hive queries with lower latency. Like many NoSQL databases, HBase does not support complex transactions, SQL, or ACID transactions. However, HBase offers high read and write performance and is used in several large applications, such as Facebook’s Messaging Platform. By default, HBase uses HDFS for durable storage, but it layers on top of this storage fast record-level queries and updates, which “raw” HDFS doesn’t support. Hence, HBase is useful when fast, record-level queries and updates are required, but storage in HDFS is desired for use with Pig, Hive, or other MapReduce-based tools.
Cassandra
Cassandra is the most popular NoSQL database for very large data sets. It is a key-value, clustered database that uses column-oriented storage, sharding by key ranges, and redundant storage for scalability in both data sizes and read/write performance, as well as resiliency against “hot” nodes and node failures. Cassandra has configurable consistency vs. availability (CAP theorem) tradeoffs, such as a tunable quorum model for writes.
Some users of Cassandra include Target and Facebook. DataStax is the firm who provides the support and tools behind this open source project.
MarkLogic
MarkLogic is a document-oriented database platform that has a schema-agnostic data model for storing and managing XML, JSON, RDF, and Geospatial data. It uses a distributed, scale-out architecture, claims to provide ACID transactions, and government-certified security.
DynamoDB
DynamoDB is Amazon’s highly scalable and available, key-value, NoSQL database. DynamoDB was one of the earliest NoSQL databases and papers written about it influenced the design of many other NoSQL databases, such as Cassandra.
Couchbase
Couchbase is a key-value NoSQL database that is well-suited for mobile applications where a copy of a data set is resident on many devices, where changes can be performed on any copy, and copies are synchronized when connectivity is available. Think of how an email client works with local copies of your email history and corresponding email servers.
Redis
Redis is a key-value store with the specific support for fundamental data structures as values, including strings, hash maps, lists, sets, and sorted sets, whereas most key-value stores have limited understanding of a value’s meaning, except to represent the value as column cells, if many cases. For this reason, Redis is sometimes called a data structure server. Redis keeps all data in memory, which improves performance, but limits the data set sizes it can manage. Durability is optional, by periodic flushing to disk or writing updates to an append log. Master slave replication is also supported.
Datomic
Datomic is a newer entrant in the NoSQL landscape with a unique data model that remembers the state of the database at all points in the past, making historical reconstruction of events and state trivial. Many standard database operations are supported, including joins and ACID transactions. Deployments are distributed, elastic, highly available.
Riak
Riak is a fault-tolerant, distributed, key-value NoSQL database designed for large-scale deployments in cloud or hosted environments. A Riak database is masterless, with no single points of failure. It is resilient against the failure of multiple nodes and nodes can be added or removed easily. Riak is also optimized for read and write-intensive applications.
Popular Posts

In the ever-changing world of global finance,...
The Internal Revenue Service (IRS) is facing a...

In the echoing corridors of Pearson Specter Litt,...